ICVPIG Conference
Highlight research from The Indian Conference on Computer Vision, Graphics and Image Processing 2018
In this blog, I highlight some of the research work that got my attention at ICVPIG 2018.
I recently had the pleasure of attending The Indian Conference on Computer Vision, Graphics and Image Processing (ICVGIP) 2018 and I was taken away by the interesting and diverse problems and approaches people were working on. This was my first real conference visit and it showed me the desire and seriousness of the indian community to be part of global A.I research. Having previously being exposed to a limited amount of research and researchers, it set a standard for me personally and helped me to see my place in the larger scheme of things. I saw people dedicated and fascinated by new advances and willing to challenge themselves and take on hard problems.
While I previously held up ‘A.I’ as this massive cloud that’s going to change the world, at times it felt like I was in a microcosm, a microcosm of the computer vision community, and that there were probably a lot of other microcosms out there where people believed what they were working on would change the world. It made me feel extremely small at times and I realized its more important to work on something you love rather than something you think has a lot of opportunity. Since, then I’ve dug deeper to pinpoint the things that I, only I, enjoy about my work and build and a deeper appreciation of some of the important pieces of knowledge easily looked over.
I was surprised by how much I personally understood. Going through the list of events prior to the conference I actually laughed out at the fact that none of it seemed remotely comprehensible to me. I wondered if I would even understand the objective of most papers, much less their content. But it turned out that most papers with daunting names were simple concepts with a few minor modifications and I was in much better shape than I expected. It reinforced to me the notion that spending time contemplating the basics or core elements will make understanding new things significantly easier. Overall, it was a great learning experience and I will definately be re-attending.
1) Challenges and Advances in Vision-Based Self-Driving - Manmohan Chandraker
This workshop was on self driving cars and while I didn’t understand nearly all of it, I was introduced to multiple new concepts that I was able to grasp. Firstly, metric learning. Metric learning is transforming your inputs into a space where euclidean distance in that space corresponds to differences in the classes ( two images can have smaller difference in pixel intensities but be of different classes compared to two images of the same class in regular pixel space. Think why Nearest Neighbour classification for images fails.)
Knowledge Distillation
I was quite happy to learn about this. The reason being that when I was learning about style transfer networks involving the minimization of the difference between intermediate layers of a larger pretrained model and our smaller style network, I wondered if we could make a small network copy the behavior of a larger one in this manner. And this is exactly what knowledge distillation is.
Knowledge distillation is a network compression technique where we train one large powerful network( Teacher Network) and now want a smaller network(Student Network) to mimic its behavior. So we include a term in the loss (1-a)(Te-Ts) which is the difference of the softmax outputs of both classes. The goal is to make the layer distributions of both the network as similar as possible.

This was also done for interminate layers with an adaptation layer in between( to adjust for the difference in number of filters of each network) that projects that layers output to the same fixed size space where they can be compared.

Deep Supervision Manmohan Chandraker is one of the authors on the first paper on Deep Supervision. Deep Supervision is when you present your network with intermediate concepts along its path so its learning is more guided. An example would be suppose I am training a segmentation network, so somewhere along the way I can have a side channel where I compute the loss of the channel with a downsampled version of my target. This makes learning more smooth and structured as the network is guided to interminate concepts that supplement its learning of the main task (very popular with Unet). Ideally we want the representations of our conv layer and secondary target to be semantically similar so we don’t add much processing, maybe just a layer or two to get it to the appropriate dimension to compute the loss.

Spatial Transformer
Spatial transformers identify the target area in an image( by the activation maps) and perform data augmentation to that part of the image such as stretching, zooming, rotating etc so as automatically create data augmentations that make the network’s representations more robust.

2) Semantic Segmentation - Girish Varma
Link to Paper Here we were introduced to the Indian Driving Dataset(IDD) made my Intel and IIIT Hyderabad which has 34 annotated labels. It is composed of roads in and around Hyderabad and IIIT.

We were shown why models trained on traditional datasets such as CityScapes do not transfer to Indian roads due to their unstructured nature, non-homogeneous conditions and ambiguous road boundaries. Not only that but there is alot of overlap between pedestrians and vehicles in the center or roads which is not present in most driving datasets. Signboards and vehicle shapes also differ. Models trained on road conditions outside India cannot adopt to Indian roads very easily.

We were told about the state of art segmentation networks like PSPNet and Deeplab. They found that model trained on IDD do better when transferred to other datasets compared to models trained on other dataset transferred to IDD. Because of the diversity of IDD, it is a more robust dataset for domain adaptation. Authors used an interesting mixed supervised learning strategy where they mix the validation data into training without using the validation masks. They take their validation data and use their current model’s predictions to make the model more confident without using the validation masks( you may have encountered a modification of this in kaggle segmentation challenges). They kept a running mean of the last features maps for each class separately. They rely on labeled data to make a model get a good representation and when the model predicts an outcome of say 0.6 score on unlabeled validation data they push the representations in the last conv layer to those of the mean of that class making the score slowly to increase to 1. This is done by making the internal representation closer to the of the running distribution of that class. Initially, this will work very poorly but later the model will be more trustworthy on unlabeled data. Doing this gave them a good score increase.
3) Keep On Learning by Tinne Tuytelaars
This planetary talk was on sequential learning and how we can get neural networks to continue training once deployed in the wild under a variety of different constraints. This talk was one of the best talks at the conference especially given that I had never before been introduced to this problem set. This talk made me think about crucial issues and facets of deploying neural networks that I had previously ignored. Understanding how disentangled representations affect learning is something I have been looking into since.
Sequential learning, also referred to as continual, incremental, or lifelong learning (LLL), studies the problem of learning a sequence of tasks, one at a time, without access to the training data of previous or future tasks. Our main objective is : How do we add new classes to a model that is already trained on some finite number of classes?

There are several naive approaches. One would be to simply add nodes for the extra classes in the softmax layer and train the model as the classes come. However this leads to the problem of ‘catastrophic forgetting’ where the network erases representations it learned for classes earlier in favor of the newer classes. Another approach following this would be fix the feature layers and only train the classifier at the end. However the model then may not pickup on essential features which it does not have the appropriate filters for as the early filters are fixed. This is problematic when the class differences get small such as among household objects. Another approach would be just to train several model again and again or have separate models for new and old classes; the problems in both approaches can be easily inferred.
Memory Aware Synapses

In this work we try to make the neuron representations dense and individually prominent rather than having the information spread among many thousands of neurons. We train our initial model and identify critical weights crucial for each class. Accordingly, we assign a weight to each neuron propotional to it’s level of importance. Later, when we introduce new classes we penalise changes to the neurons depeding upon their given weight. Let \(\Omega_{ij}\) denote the weight given to the i’th neuron in the j’th layer and let to the old and new proposed weights be denoted by \(\Theta_{ij}\) and \(\Theta_{ij^{*}}\).
Then to our loss function we add a new regularising term which can be seen in the above image.
The weights are found by the effect that changing them has on the loss. \(\frac{dL}{dw_{ij}}\), is computed for each parameter and then the avgerage is taken over all points in our dataset. By our dataset I mean the one in which we expect our model to perform on. This is important as if we are using a model pretrained on ImageNet and dont require knowledge of certain casses then the model can forget those classes by associating a low cost to changing weights associated with those classes. This act of penalizing changes to important weights is called Weight Consolidaion.
Self-less Sequential Learning

Our motivation here is to encourage model sparsity, i.e even if our model is of large size the information required for the target is concentrated within few neurons rather than being distributed all over. This will help us repurpose the other neurons when more classes are entered. Learning a disentangled representation is more powerful and less vulnerable to catastrophic interference. In fact if we make neurons individually representative, then the need to overwrite and forgot past classes decreases. Changing few neurons in a tanged representation would mess up the different tasks each contributes to.
They achieve this by, firsty penalising changes to important weights as last time, and local penalization of correlated weights. For in depth details please check out their paper, but briefly : they impose a soft form of constraint that caps the number of highly activated neurons per layer. Firstly, the index of the activation maps are kept fixed( as always) and around the neighbourhood of each neurons, say m indexes to the right and left, we penalise neurons if they are jointly activated. So within every 2m indexes, we try to have only one neuron activation. This limits the number of high activations to N/2m per layer where N is the number of neurons in the layer. This forces the network to have few neurons of high activation per layer any time an example is passed through, making each neuron learn a dense representation for the target.
Here we have an interesting association with Hebbian Learningin the brain. For more reading about why disentangled representation help with overfitting please see this interesting paper “Reducing Overfitting in Deep Networks by Decorrelating Representations”
11link
4) Wadhwani AI P Andandan
This was a different talk than all the rest in that it was the only non-technical talk at the conference. Wadhwani A.I is a non-profit institute based out of Mumbai started by the Wadhwani brothers with the aim of using A.I to benefit the lower income parts of the indian community that had not benefited much from technological advancement. The problems the institute is currently tackling are - High risk pregnancies, Anthropometry(infant mortality), Tuberculosis Eradication and Cotton Farming. The institute has strong backing of the Indian Government and was inaugurated by Narendra Modi in 2018. Wadhwani A.I also has partners such as Gates Foundation and WISH Foundation in some of its endeavors. While Wadhwani A.I is a research institute, it focuses on practical problems and interactions with the community that can have an impact in the short-term. They have started working on a number of healthcare related issues that have yet to benefit from advancements in A.I in the healthcare domain.
5) Learning to Read by Spelling - Ankush Gupta, Andrew Zisserman
This is a unsupervised learning method of text recognition from images using a GAN. I found this method very novel and overall a clean and effective approach. They aim to reduce the amount of annotations by using images of text to train the network on identifying text character by character.

A convolution neural network is used with a fixed receptive field to read the input text image. he network is trained on snippets of text like above which are less than or equal to some fixed character length - L. Our softmax layer then has L outputs and we predict zero vectors for space/empty regions(if the sentence is shorter than L). The convolutional network produces scores for each segment and by doing so produces a sentence in the end. The idea is that as our network learns to spell and get individual characters correct, the text generated by it will be valid enough to fool a discriminator that discriminates between real and generated strings.

From the paper “lexically valid text strings form a tiny sub-space of all possible permutations of symbols,e.g.there are only ≈13k valid English words of length 7, as opposed to almost 8 billion permutations of the 26 English letters. “
This method uses a bank of english words, like a dictionary, to check if the outputs are valid words or not. By getting individual words correct, the generator learns to form sentences as “relative frequencies of the characters and their co-occurrence patterns impose further constraints (see section 5.3 for correlation between character-frequency and learning). These constraints combined with strong correlation between the input image and the predicted characters are sufficient to drive learning successfully”

The also use an RNN to adopt for different sequence lengths and get good results. Do check out their detailed paper.
6) Dynamic Image Networks for Human Fall Detection in 360-degree Videos
(Unpublished)
This paper was on aimed at detecting abnormal behavior(falls) in retirement homes from installed cameras. Here they used a very interesting approach to compress the large amount the video data into a single 2D image. This method uses optical flow and rank pooling to Compress 3D images to 2D and was developed in the paper “action recognition with dynamic image networks” . This large amounts of 3D video is extremely sparse which makes optimization very difficult if we directly train on the raw video. We would need massive amounts of data for the model to figure out what is correlated with the target output. Here, the authors use this technique effectively as a fall has a different velocity than any other action, so this method is able to capture this unusual movement and have a region of high weights in that location. They pass multiple 2D slices of about a 100 frames each into a recurrent network for the final classification.
7) Jointly Learning to Compress and Identify Radiology Images - E.Ranjan et al
(Unpublished)
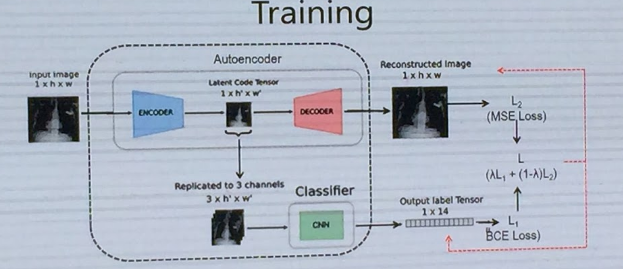
We have some input of dimension 1hw and we would like to use a pretrained imagenet model for this, however these models require an input size of 3244244. So instead of manually resizing the image we first train an autoencoder to reconstruct the image with the latent space dimension being 1244244. We then take this and copy it across 3 channels to get 3244244 and pass this into out pre trained classifier. We jointly reduce the a linear combination of the autoencoder and classifer loss and gradually make the autoencoder coefficient go to 0. As of presenting, authors claimed state of art results on ChestX.